一、基本信息
(略)
二、实验目的
要求学生掌握Socket编程技术及令牌总线协议工作过程
三、基础实验内容
Ⅰ、traceroute
1、实验目的:熟悉traceroute的使用
2、实验内容: 用traceroute测量到163网站(www.163.com)和到微软公司(www.microsoft.com)网站的路径。分析测量结果。
3、实验流程及结果
在Ubuntu上下载安装traceroute
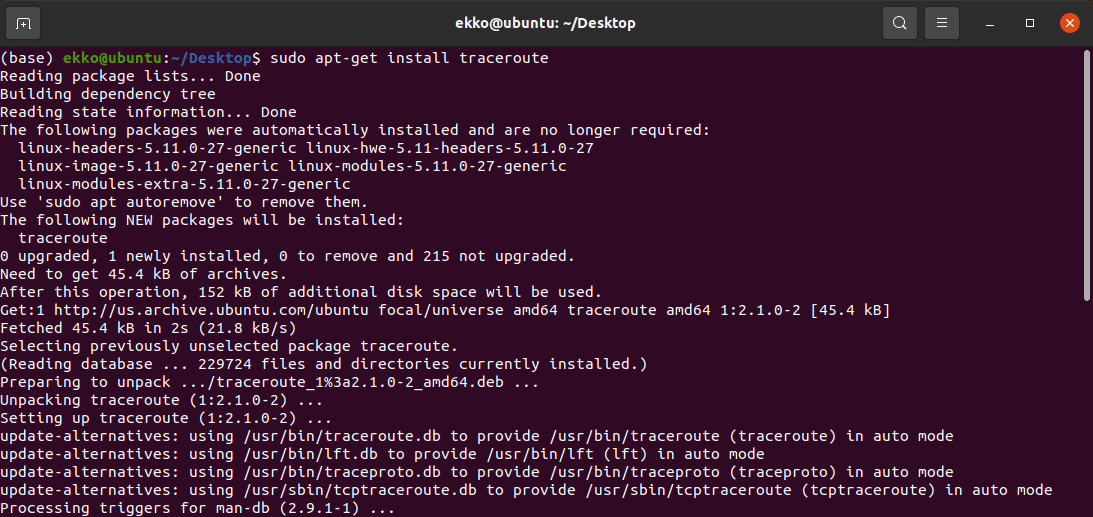
用traceroute测量到163网站(www.163.com)的路径
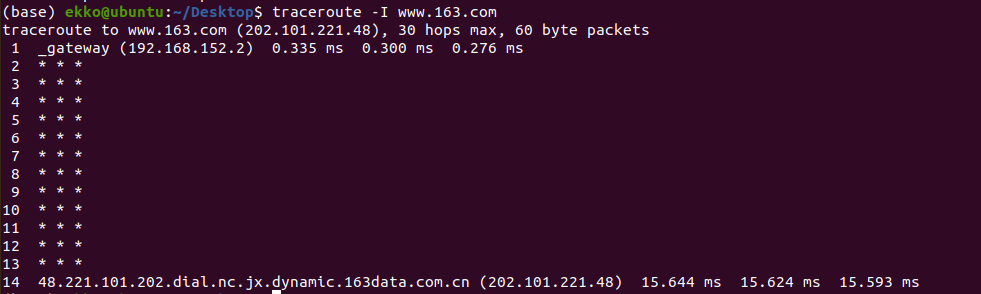
用traceroute测量到微软网站(www.microsoft.com)的路径
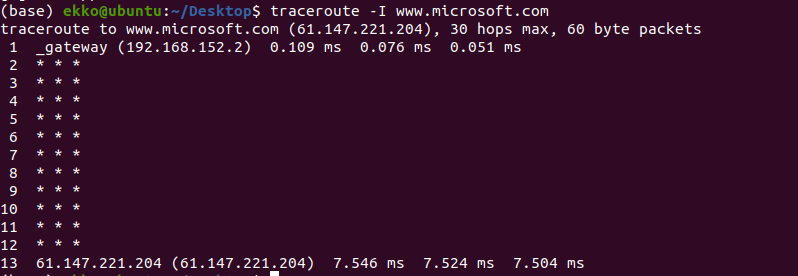
上述输出信息显示了跟踪到的路由地址信息。记录从序号 1 开始,每个记录就是一跳,而每一跳表示经过的一个网关。记录给出了每个网关对应的IP地址。其中,为 * 的记录表示可能被防火墙拦截的 ICMP 的返回信息。
在linux上使用traceroute,默认使用udp协议,除了第一跳,剩下的都是 *。是因为虚拟机 nat 路由器,默认丢弃port>32767的包。在命令中加入 -l 强制使用ICMP得到上图结果。
Ⅱ、wireshark
1、实验目的:熟悉wireshark的使用
2、实验内容:下载安装wireshark软件,设置捕获条件,用wireshark捕获数据包,对以太网帧和IP数据包进行分析。
3、实验流程及结果
Wireshark 是一个免费开源的网络数据包分析软件。它的功能是截取网络数据包,并尽可能显示出最为详细的网络数据包数据。
下载安装Wireshark并启动
查询网卡
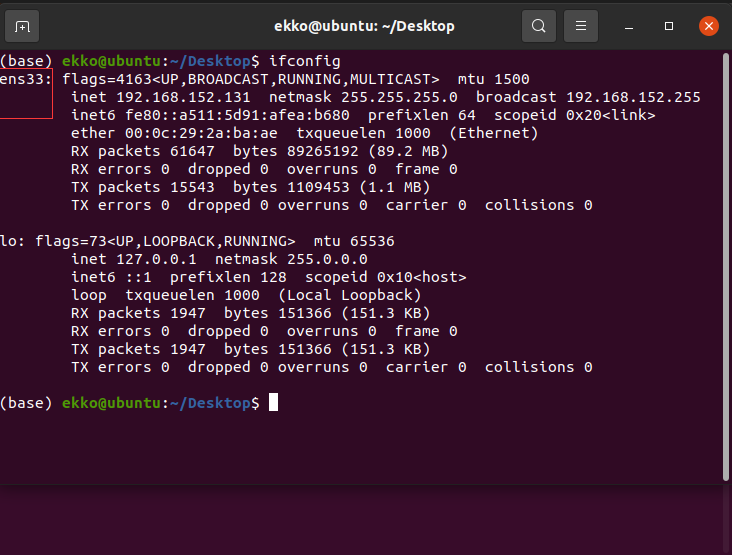
打开火绒浏览器开始发包测试
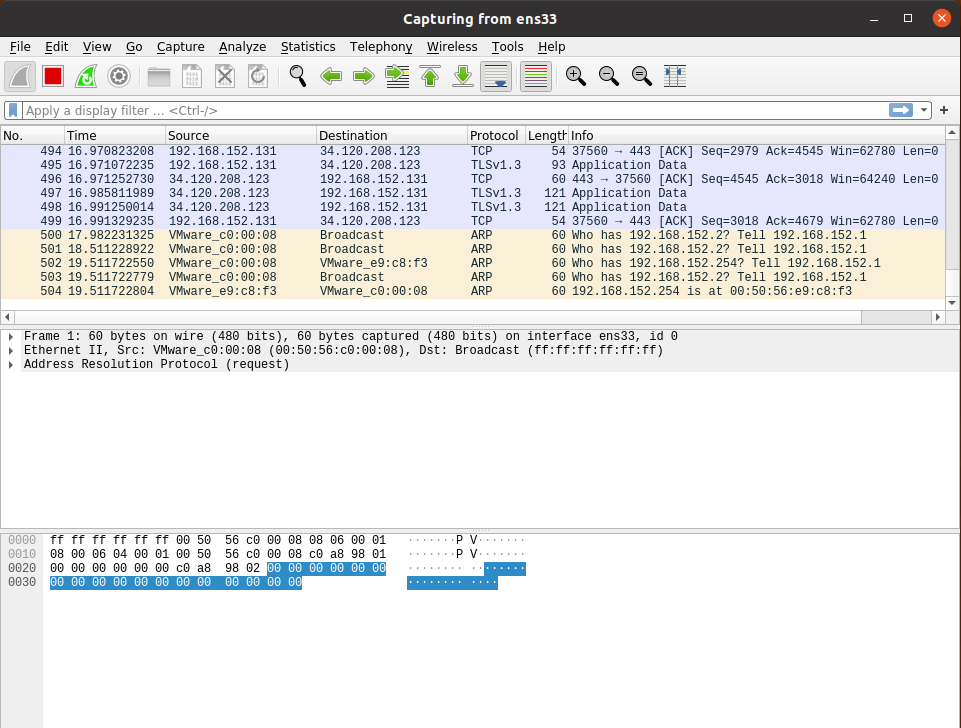
TCP找目的地址,捕获数据包,对以太网帧和IP数据包进行分析。
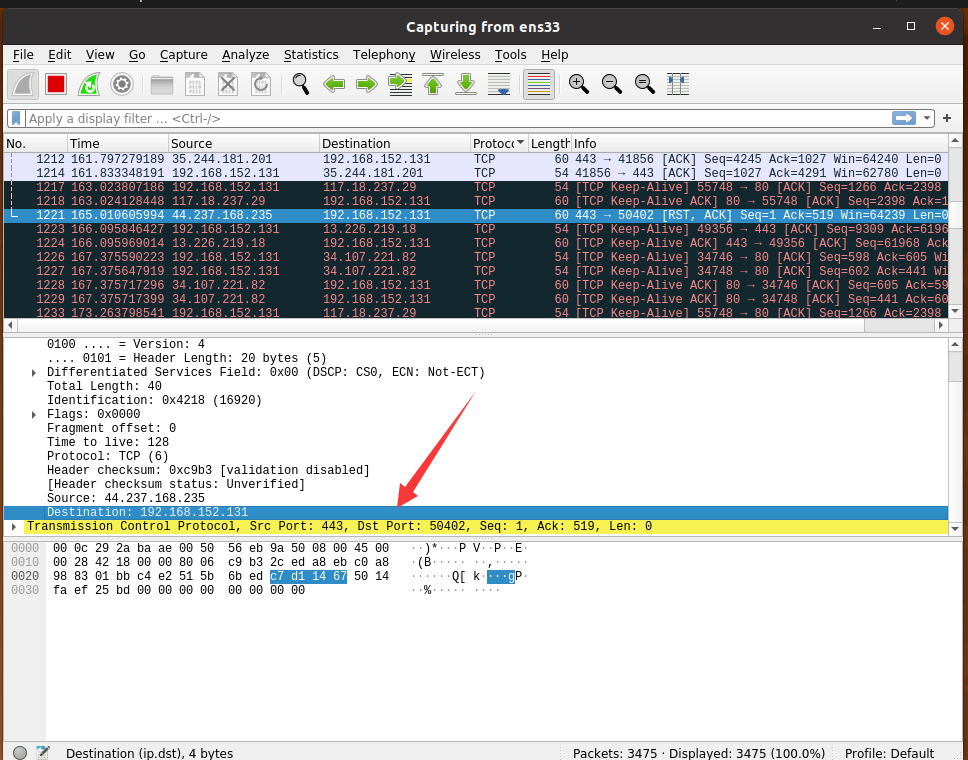
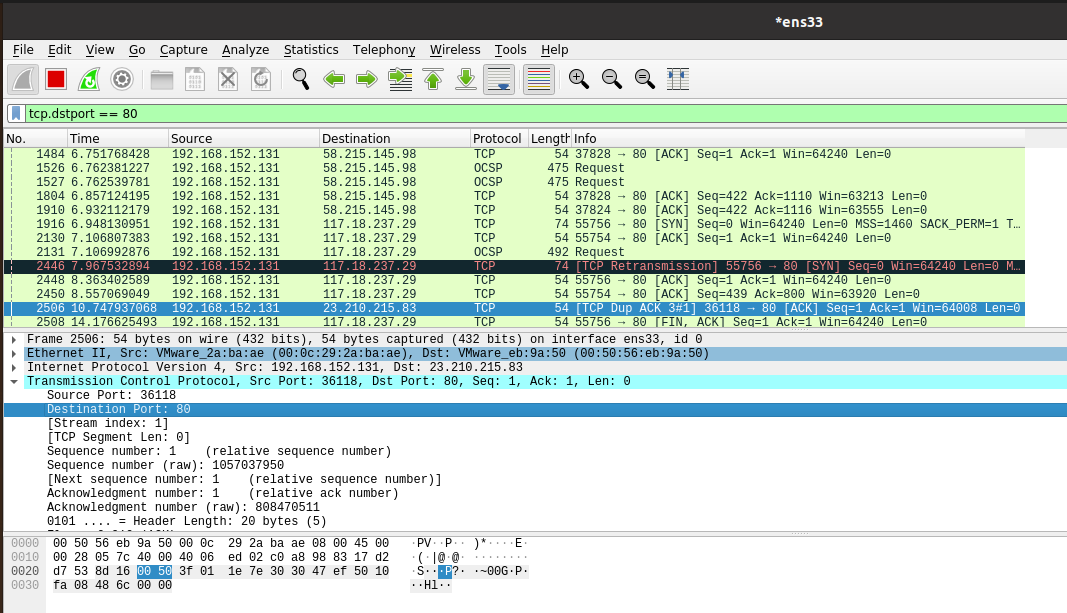
将 TCP 80 端口 作为过滤条件进行筛选分析
四、工程性实验内容
Ⅰ、Robots协议
具体内容:查看淘宝网的Robots协议,了解抓取网站数据需要遵循的规则
Robots协议的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不可以爬取。这个协议是互联网中的道德规范,虽没写入法律,但应遵守。在网站末尾加/robots.txt可以进行查看。
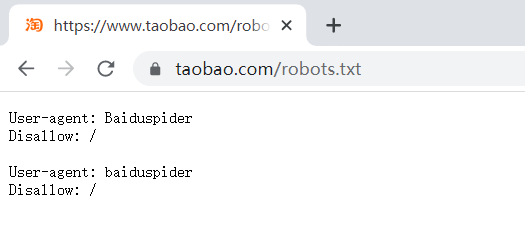
Robots协议的语法:#注释,*代表所有,/代表根目录。
无robots协议的网站,信息可以爬取。
自动或人工识别robots.txt,再进行内容爬取,Robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险。访问量很小的可以遵循,访问量大的建议遵循。非商业的建议遵循,涉及商业利益的必须遵循,爬取全网信息必须要遵循。如果是类似人类行为的爬取信息,可不遵循。
Ⅱ、 搜索关键词查询确定其关键词的查询接口
以豆瓣图书为例,进入豆瓣读书网站

随便点击一本书,观察其网址
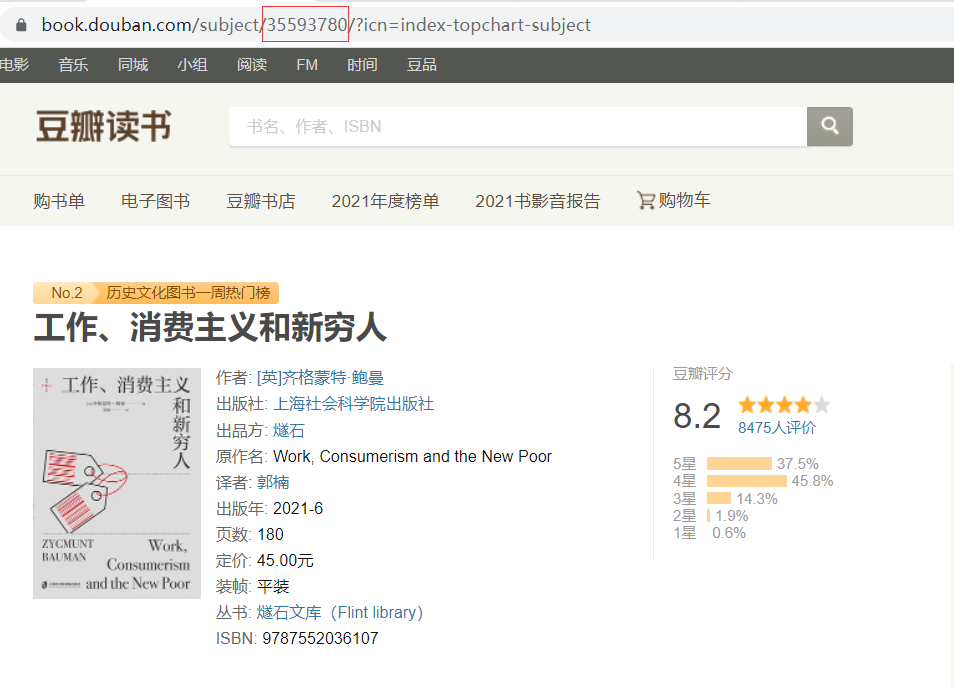
观察到红框部分即为该书在豆瓣数据库中的代号
进入短评部分
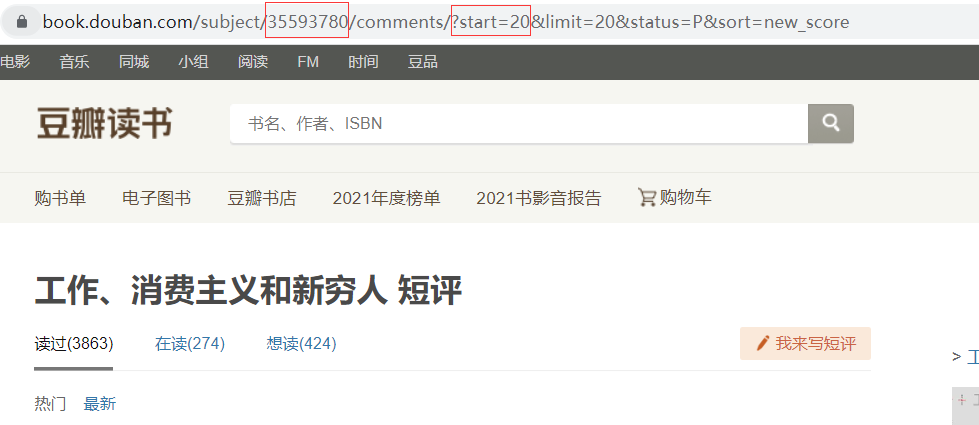
观察到前一个红框部分为该书的代码,后一个红框部分为这一页短评的起始标号,豆瓣书籍网页版一页共有20条短评,所以 start = num (num从0开始并且为20的整倍数)
1 | url = "https://book.douban.com/subject/{}/comments/?start={}&limit=20&status=P&sort=new_score" |
所以之后对豆瓣图书评论的查询靠替换关键字完成
Ⅲ、爬取豆瓣图书评论
具体内容
抓取豆瓣读书中对某本书的前50条短评内容并计算星级评定分数的平均值(保留两位小数)
实验步骤
TCP协议:传输控制协议(Transmission Control Protocol,缩写为TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议,它能提供高可靠性通信(即数据无误、数据无丢失、数据无失序、数据无重复到达的通信)。
主要适用的场景:
适合于对传输质量要求较高,以及传输大量数据的通信。
在需要可靠数据传输的场合,通常使用TCP协议。
HTTP/HTTPS等即网络服务都采用TCP协议。
TCP通信需要经过创建连接、数据传送、终止连接三个步骤。
初始化 url ,并通过 get() 函数逐网页爬取网页源代码
1
2
3
4
5url = "https://book.douban.com/subject/{}/comments/?start={}&limit=20&status=P&sort=new_score"
for index in range(0, 60, 20):
# booknum 为豆瓣书籍编号,本实验选用的是35593780
u = url.format(str(booknum),str(index))
r = get(u)创建 socket 实例,处理 https 的库
1
2
3
4def get(url):
host = 'book.douban.com'
path = url[23:]
s = ssl.wrap_socket(socket.socket())初始化端口,与主机建立起连接
1
2port = 443 # 端口 https 默认端口443
s.connect((host, port)) # 建立起连接,连接主机设置报文格式
1
2# 报文格式: GET+空格+com后面的部分+空格+HTTP/1.1(或1.0)+\r\n+Host:+域名+\r\n\r\n
request = 'GET {} HTTP/1.1\r\nHost: {}\r\n\r\n'.format(path, host) # 构建请求发送请求并接受数据
1
2
3
4
5
6
7
8
9s.send(request.encode('utf-8')) # 发送请求 转码,将str 转成bytes类型
response = b''
while True:
# 接受数据
r = s.recv(1024)
response += r
if len(r) < 1024:
break
response = response.decode('utf-8') # 解码对数据进行查找分析
此处主要使用 str 类型所带的 find() 函数
Python find() 方法检测字符串中是否包含子字符串 str
如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
1
2
3
4
5
6
7
8
9# html 为字符串
# userstart 为每个用户所在源代码的开始位置
# userend 每个用户所在源代码的结束位置
# start_str为所查询字符串的前部分
# end_str为所查询字符串的后部分
def getdata(html, userstart, userend, start_str, end_str):
start = html.find(start_str, userstart, userend)
end = html.find(end_str, start)
return 0 if start == -1 else html[start + len(start_str):end]对于星级的平均分计算,考虑到有些用户没有打分,计算平均分时需将其删除。对于上面的数据查询函数 getdata() ,如果未能查询到该用户所打的分数,则在star[] 数组中写入0,若查询到所打的分数,则写入该分数。
将结果进行整理输出
1
2# douban.txt 文件和当前py文件位于同一目录之下
output = open("douban.txt",'w',encoding='UTF—8')
将50条评论逐行输入至 douban.txt 文件中,在第51行输入平均分数,第52行输入书名。
可视化界面
该可视化界面采用 Unity3D 制作,版本为 2021.2.7f1c1,所用语言为 C#
【展示】

[1] 处按钮为显示前页评论
[2] 处按钮为显示后页评论
[3] 处为书名显示区域
[4] 处为所求得的平均分数(保留两位小数)
[5] [6] [7] [8] 处为评论内容显示区域,可上下拖拽查看全部内容
【代码及主要制作思路】
创建一个string类型的数组,用以存储评论、书名、分数等数据
1 | string[] txt |
使用绝对路径读取上述 douban.txt 文件
1 | using System.IO; |
此时 txt 数组共有52个元素,存储50条评论、一个书名、一个平均分数
新建 TEXT 类型数组 comments 并与UI上的组件进行绑定,将书名和分数直接显示。
1 | comments[0] = transform.GetChild(7).GetComponent<Text>(); |
调用按钮点击相应事件,为 ‘前页’ ‘后页’ 按钮绑定相关操作
1 | upbtn.onClick.AddListener(setindexup); |
最后在 Update() 函数中逐帧进行赋值操作,达到动态刷新的效果
1 | void Update() |
Ⅳ、抓取道指成分股数据
具体内容
在https://money.cnn.com/data/dow30/ 上抓取道指成分股数据并解析其中30家公司的代码、名称和最近一次成交价,将结果放到一个列表中输出。
实验步骤
采用 request 和 re 两个包来解决
1 | import requests |
确定查询网址路径
1 | url = 'https://money.cnn.com/data/dow30/' |
由于网址发生变化,所以实际进入的网址为

通过r=request.get(url)构造一个向服务器请求资源的url对象。
这个对象是Request库内部生成的。
这时候的r返回的是一个包含服务器资源的Response对象。包含从服务器返回的所有的相关资源。
1 | r = requests.get(url) |
根据网页源代码,构建查匹配对应数据所需的正则表达式

1 | pattern = re.compile( |
进行匹配查询
1 | # data 为一个含有4个元素的元组,包含所需数据 |
数据处理:对数据进行筛选比对,选取所需要的 【公司的代码】、【名称】、【最近一次成交价】
1 | for i in data: |
输出示例:
1 | for i in dowdata: |
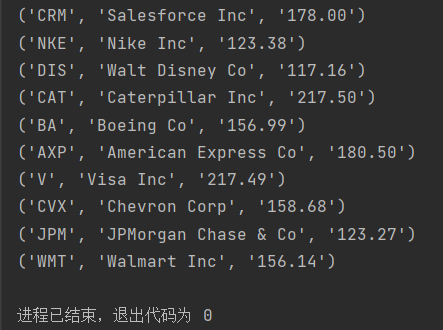
该结果对应时间:2022.4.28 -17:41