Ⅰ、暗通道先验图像去雾霾
参考论文:K. He, J. Sun and X. Tang, “Single Image Haze Removal Using Dark Channel Prior,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 12, pp. 2341-2353, Dec. 2011.
阅读地址:https://readpaper.com/pdf-annotate/note?noteId=696733953373192192&pdfId=4531190175211610113
一、论文简介
在本文中,作者提出了一种简单而有效的图像先验-暗通道,用于去除单个输入图像中的雾霾。暗通道先验是一种对室外无雾图像的统计。它是基于一个关键的观察-在室外无雾图像中的大多数局部斑块包含一些像素,其强度在至少一个彩色通道非常低。利用这一先验和烟雾成像模型,我们可以直接估计雾霾的厚度,并恢复一幅高质量的无雾霾图像。在各种模糊图像上的结果表明了所提出的先验方法的有效性。
二、具体过程介绍
在计算机视觉领域,存在一个对于雾霾图像的模型定义:
其中
最终目标:从
1、暗通道图像
根据原文中的公式获取暗通道图像并进行腐蚀操作
1 | def DarkChannel(image, size): |
腐蚀前:

腐蚀后:

2、大气光值
由论文可知,如果有一个图像中,存在一个无限远的距离的像素存在,这个时候,此像素的透射率几乎为0。这个图像中最亮最亮的值所在的像素可以被看做是雾遮盖的程度最大也是其值可以看做是几乎等同于
我们可以从暗通道图中求取大气光值
- 在暗通道图中按照亮度的大小提取最亮的前0.1%的像素
- 在原始雾图I(x)中找对应位置上具有最高亮度的点的值,此处我们通过累加求平均值获得相对稳定值
1 | def Atmospheric_light(image, dark_channel): |
3、透射率
根据已有公式,论文中经过推导得到的透射率计算公式如下:
1 | def TransmissionEstimate(image, A, size): |
根据论文中的说明,实际上,$\min\limitsc (\min\limits{y \in \Omega(x)} ( \frac{I^c(y)}{A^c}) )
4、引导滤波 (Guided Filter )
(该部分为优化效果,未在原文中提出,此处的实现主要参考自 https://zhuanlan.zhihu.com/p/36813673)
(同时opencv 3.0 中也添加了guided filter的API,可以直接调用)
引导图滤波器是一种自适应权重滤波器,能够在平滑图像的同时起到保持边界的作用
优点:
- 能够克服双边滤波的梯度翻转现象,在滤波后图像的细节上更优
- 较之传统双边滤波效率高,时间复杂度为O(N),N是像素个数
原论文中的 Guided Filter 的伪代码如下
依照该伪代码在python中使用 opencv 实现如下:
1 | def Guidedfilter(image, p, r, eps): |
【未使用引导滤波的结果】

【使用引导滤波的结果】

5、去雾之后的结果图像
由论文中的公式
可得
1 | def Recover(image, t, A, t0 = 0.1): |
在论文中提到一般给
三、实验结果及分析
【实验结果】


当去雾之后,画面整体颜色偏暗,对比度较高
不过我在实验中发现对一下代码进行修改可得到一些不同的结果
1 | def TransmissionEstimate(image, A, size): |

在计算透射率时直接对原图除以大气光强,可以使得最终结果更加明亮,类似一种高对比度、高曝光的效果
在整个实验中,Guided filter起到了很大的作用,并且一开始为用任何优化实现原文时,得到的结果并不好,对于数据集中的雾霾较为浓厚的图片,整体有一种偏蓝的效果,我猜测应该是图片大多位于室内,再加上人为造成了浓雾弥漫的效果,使得大气光值的计算出现了问题。
Ⅱ、超分辨率算法 Real-ESRGAN 和 Real-CUGAN
一、相关论文及链接
腾讯——《Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data》
论文地址:https://arxiv.org/pdf/2107.10833.pdf(下文中所以公式及图片均引用自该论文)
项目地址:https://github.com/XPixelGroup/BasicSR
B站——《Real Cascade U-Nets for Anime Image Super Resolution》
项目地址:https://github.com/bilibili/ailab/tree/main/Real-CUGAN
超分重建相关数据集下载地址:https://data.vision.ee.ethz.ch/cvl/DIV2K/
Squirrel Anime Enhance下载地址:https://github.com/Justin62628/Squirrel-RIFE/releases/tag/v0.0.3
二、超分辨率
1、简介
超分辨率是计算机视觉的一个经典应用。SR是指通过软件或硬件的方法,从观测到的低分辨率图像重建出相应的高分辨率图像(说白了就是提高分辨率),在监控设备、卫星图像遥感、数字高清、显微成像、视频编码通信、视频复原和医学影像等领域都有重要的应用价值。
传统的超分辨率重建技术有基于插值的图像超分辨率和基于重建的图像超分辨率等
2、基于深度学习的图像超分辨率重建技术
基于深度学习的图像超分辨率重建的研究流程如下:
首先找到一组原始图像 Image1
然后将这组图片降低分辨率为图像 Image2
通过各种神经网络结构,将 Image2 超分辨率重建为 Image3
比较Image1与Image3,验证超分辨率重建的效果,根据效果调节神经网络中的节点模型和参数
反复执行,直到达到较好的效果
3、两种常用的评价超分的指标——PSNR和SSIM
对超分辨率的质量进行定量评价常用的两个指标是 PSNR (Peak Signal-to-Noise Ratio)和SSIM(Structure Similarity)。这两个值越高代表重建结果的像素值和标准越接近。
PSNR(Peak Signal to Noise Ratio)峰值信噪比
其中 MSE 表示当前图像 X 与参考图像 Y 的均方误差,H、W分别为图像的高和宽,n为每像素的比特数(比如灰度图的单个像素占8bit)
PSNR 的单位是 db,数值越大表示失真越小
SSIM(Structure Similarity )结构相似性
其中
是用来维持稳定的常数,
结构相似性的范围为-1到1,当两张图像一模一样时,SSIM的值等于1。
三、Real-ESRGAN
由腾讯ARC实验室发表。在单张图片超分辨率(Single Image Super-resolution)的问题中,许多方法都采用传统的 Bicubic 方法实现降采样,但是这与现实世界的降采样情况不同,太过单一。盲超分辨率(Blind Super-resolution)旨在恢复未知且复杂的退化的低分辨率图像。根据其使用的降采样方式不同,可以分为显式建模(explicit modeling)和隐式建模(implicit modeling)。
- 显式建模:经典的退化模型由模糊、降采样、噪声和 JPEG压缩组成。但是现实世界的降采样模型过于复杂,仅通过这几个方式的简单组合无法达到理想的效果。
- 隐式建模:依赖于学习数据分布和采用 GAN 来学习退化模型,但是这种方法受限于数据集,无法很好的泛化到数据集之外分布的图像
【降级模型】
First-order降级模型如下:
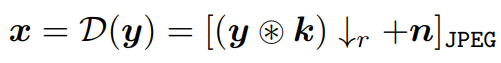
其中,x代表降级后的图像,D代表降级函数,y代表原始图像,k代表模糊核,r代表缩小比例,n代表加入的噪声,JPEG代表进行压缩。
在现实世界中,图像分辨率的退化通常是由多种不同的退化复杂组合而成的。
因此,作者将经典的一阶退化模型(“first-order” degradation model)拓展现实世界的高阶退化建模(“high-order” degradation modeling),即利用多个重复的退化过程建模,每一个退化过程都是一个经典的退化模型。但是为了平衡简单性和有效性,作者在代码中实际采用的是二阶退化模型(“second-order” degradation model)。流程如下图所示:
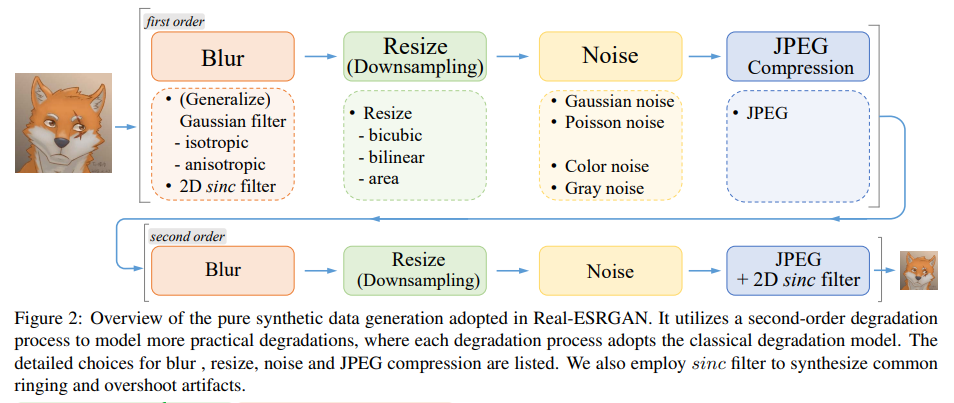
- 对于模糊核k,本方法使用各项同性(isotropic)和各向异性(anisotropic)的高斯模糊核。
- 对于Resize操作,常用的方法又双三次插值、双线性插值、区域插值—由于最近邻插值需要考虑对齐问题,所以不予以考虑。在执行缩小操作时,本方法从提到的3种插值方式中随机选择一种。
- 对于噪声操作,本方法同时加入高斯噪声和服从泊松分布的噪声。同时,根据待超分图像的通道数,加入噪声的操作可以分为对彩色图像添加噪声和对灰度图像添加噪声。
- JPEG压缩,本方法通过从[0, 100]范围中选择压缩质量,对图像进行JPEG压缩,其中0表示压缩后的质量最差,100表示压缩后的质量最好。
First-order由于使用相对单调的降级方法,其实很难模仿真实世界中的图像低分辨模糊情况。因此,作者提出的High-order其实是为了使用更复杂的降级方法,更好的模拟真实世界中的低分辨模糊情况,从而达到更好的学习效果。
文中提出的高阶降级模型公式如下:
上式,其实就是对First-order进行多次重复操作,也就是每一个D都是执行一次完整的First-order降级,作者通过实验得出,当执行2次First-order时生成的数据集训练效果最好
【sinc filter】
之后还设置sinc filter来模拟振铃和过冲伪影现象,
其中

上图为不同截止频率下的振铃和过冲伪影效果
但是因为采用了高阶退化模型,使得退化空间相比于 ESRGAN 来说大得多,训练也就更加具有挑战性。因此作者在 ESTGAN 的基础上做了两个改动:
- 使用 U-Net 判别器替换 ESRGAN 中使用的 VGG 判别器
- 引入 spectral normalization 来使得训练更加稳定,并减少 artifacts。
【生成网络模型】
在网络模型方面,Real-ESRGAN扩展了原来的ESRGAN,同时支持x1,x2,x4。Real-ESRGAN采用与ESRGAN相同的生成网络。对于比例因子×2和×1,使用 pixel-unshuffle 操作(可理解为通过扩大图像通道而对图像尺寸进行压缩),以降低图像分辨率为前提,对图像通道数进行扩充,然后将处理后的图像输入网络进行超分辨重建。

【对抗网络模型】
由于使用的复杂的构建数据集的方式,所以需要使用更先进的判别器对生成图像进行判别。之前的ESRGAN的判别器更多的集中在图像的整体角度判别真伪,而使用U-Net 判别器可以在像素角度,对单个生成的像素进行真假判断,这能够在保证生成图像整体真实的情况下,注重生成图像细节。

【训练方法】
- 预训练一个以 PSNR 为目标的模型,并采用 L1 loss,得到 Real-ESRNet
- 用 Real-ESRNet 初始化 Real-ESRGAN 中的 Generator,然后训练 Real-ESRGAN,采用 L1 Loss、perceptual loss 和 GAN loss 三种组合的 loss。
【实验结果】

四、Real-ESRGAN 和 Real-CUGAN性能对比
详细对比(以下表格在 Real-CUGAN 项目中可见)
| Real-ESRGAN(Anime6B) | Real-CUGAN | |
|---|---|---|
| 训练集 | 私有二次元训练集,量级与质量未知 | 百万级高清二次元patch dataset |
| 推理耗时(1080P) | 2.2x | 1x |
| 效果(见对比图) | 锐化强度最大,容易改变画风,线条可能错判,虚化区域可能强行清晰化 | 更锐利的线条,更好的纹理保留,虚化区域保留 |
| 兼容性 | PyTorch支持,VapourSynth支持,NCNN支持 | 同Waifu2x,结构相同,参数不同,与Waifu2x无缝兼容 |
| 强度调整 | 不支持 | 已完成4种降噪程度版本和保守版,未来将支持调节不同去模糊、去JPEG伪影、锐化、降噪强度 |
| 尺度 | 仅支持4倍 | 已支持2倍、3倍、4倍,1倍训练中 |
五、Squirrel Anime Enhance

Squirrel Anime Enhance是一款基于多个开源超分算法的中文超分软件,具有以下优势:
- 集成了 realCUGAN, realESR, waifu2x 三种超分算法
- 拥有友好的 GUI 图形界面,方便使用
- 使用pipe传输视频帧,无需拆帧到本地,拯救硬盘
- 更小的显存、内存占用,更快的速度
- 拥有预览界面,能更好地了解超分情况
安装较为简单,解压后,双击启动SAE.bat即可启动软件
【使用方式】
在如下界面设置输入的图片或视频文件或其所在文件夹,并设置输出文件夹

在如下界面设置超分算法与模型,目前主要集成了realCUGAN, realESR,和waifu2x三种超分算法,每一种超分算法下都有相对应的超分模型。

waifu2x:
- models cunet:一般用于动漫超分
- models photo:一般用于实拍
- models style anime:一般用于老动漫
realESR:
- realESRGAN模型,目前支持2x和4x
- realESRNet模型:效果较为模糊,细节处不够精密,个人感觉不如realESRGAN模型
realCUGAN:
- up2x-latest-conservative pth
- up2x-latest-denoise_2.pth
- up3x-latest-consevative.pth
- up3x-latest- denoise_3.pth
- up4x-latest-conservative pth
- up4x-latest-denoise_3.pth
- up4x-latest-no denoise.pth
其中 Denoise 为降噪版,主要针对较多噪声的情况,conservative为保守版,处理效果较为保守,不会造成严重的失真。No-Denoise为无降噪版,较为通用。
输出分辨率预设:提供倍数及具体像素值的选择
在以上设置完成后,点击一键压制可以开始进行超分操作。
【运行界面】

六、实验结果
对于Real-ESRGAN 和 Real-CUGAN,下载其在项目地址中公布的release发行版本


通过调用一下命令来运行
1 | ./realesrgan-ncnn-vulkan.exe -i 输入图像.jpg -o 输出图像.png -n 模型名字 |
【结果展示】
分辨率说明. 由于Real-ESRGAN 目前仅支持 X4 ,所以分辨率均使用4倍 ↩
原图:分辨率为1600 × 1055

结果图:分辨率为 6400 × 4220
左为 Real-ESRGAN 右图为 Real-CUGAN

原图:分辨率为1920 × 1080

结果图:分辨率为 7680 × 4320
左为 Real-ESRGAN 右图为 Real-CUGAN

原图:分辨率为120 × 80

结果图:分辨率为 7680 × 4320
左为 Real-ESRGAN 右图为 Real-CUGAN

【结果分析】
本机环境为 Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz 2.40 和 GeForce GTX 1650 ,性能较差 ,无法用于训练。在运行耗时方面,在直接使用exe 文件运行时对于一张标准的 1920 ×1080 图片,Real-ESRGAN 耗时2分钟左右,而Real-CUGAN 仅需四五秒。目前的Real-ESRGAN 仅支持图片4倍放大超分辨率,而Real-CUGAN支持2、3、4倍,使得实验比较均使用×4分辨率进行。总体而言,B站的 Real-CUGAN 效果较好,耗时较短,从我个人的肉眼观察角度出发,腾讯的RealESRGAN纹理保留性较差,较为模糊、细节有所丢失,表现较弱,而B站的 Real-CUGAN对于分辨率较高的图片细节处更为丰富,对于原图较为明亮的图片超分后也可以很好的保持光照亮度。